Note: This is documentation for version 4.11 of Source. For a different version of Source, select the relevant space by using the Spaces menu in the toolbar above
Scenario Options
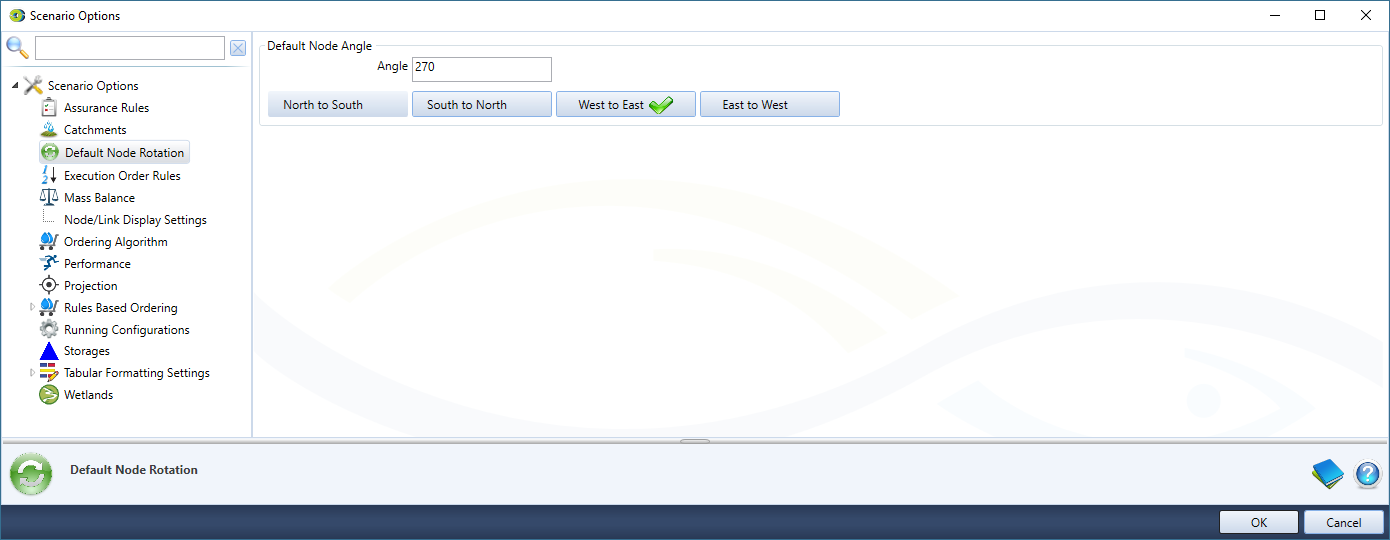
Default Node Rotation
The default node rotation can be set either by entering an angle between 0 and 359 degrees, or by clicking a compass direction button, where:
- North to South corresponds to 0 degrees
- East to West corresponds to 90 degrees
- South to North corresponds to 180 degrees
- West to East corresponds to 270 degrees.
Clicking a compass direction button will update the Angle text box with the corresponding angle, and a green tick will show on the chosen button (Figure 1).
Any nodes subsequently added to the schematic editor will have the new default direction. To change existing nodes to the default direction, select the node(s), right click and choose Rotate » Default from the contextual menu. See node rotation for more information.
Figure 1. Scenario Options, Default Node Rotation
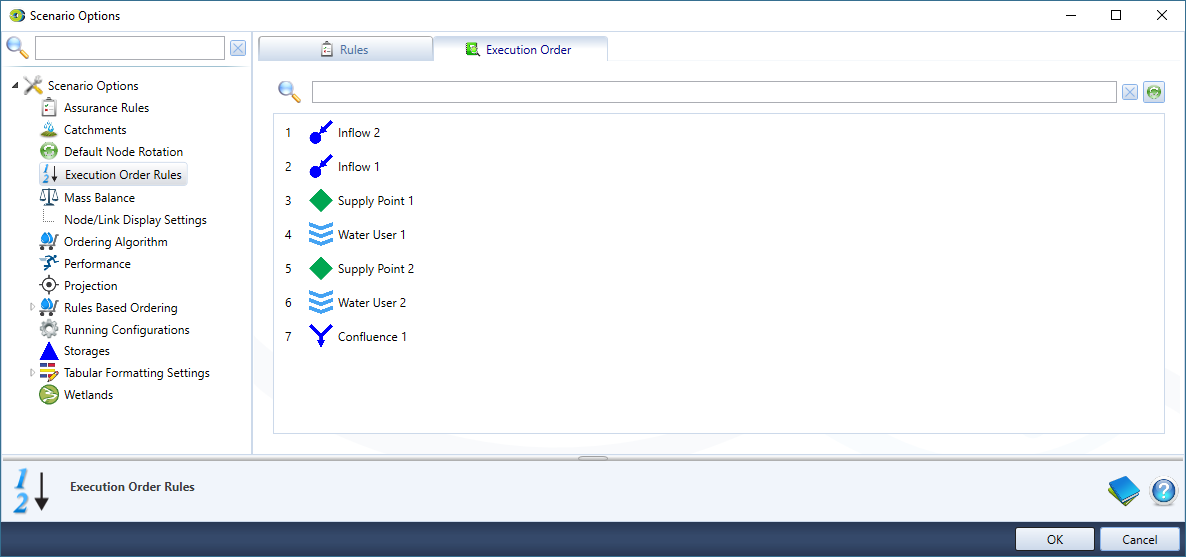
Execution Order Rules
During a scenario run, components of the scenario are run in a particular order to ensure that they comply with inbuilt Simulation phases and execution order rules. Default execution order is based on leaf node names alphabetically. Thus, renaming a node can change the order. Links are run with their upstream nodes.
Node execution order can be viewed through Execution Order Rules » Execution Order (Figure 2)
Figure 2. Scenario Options Execution Order
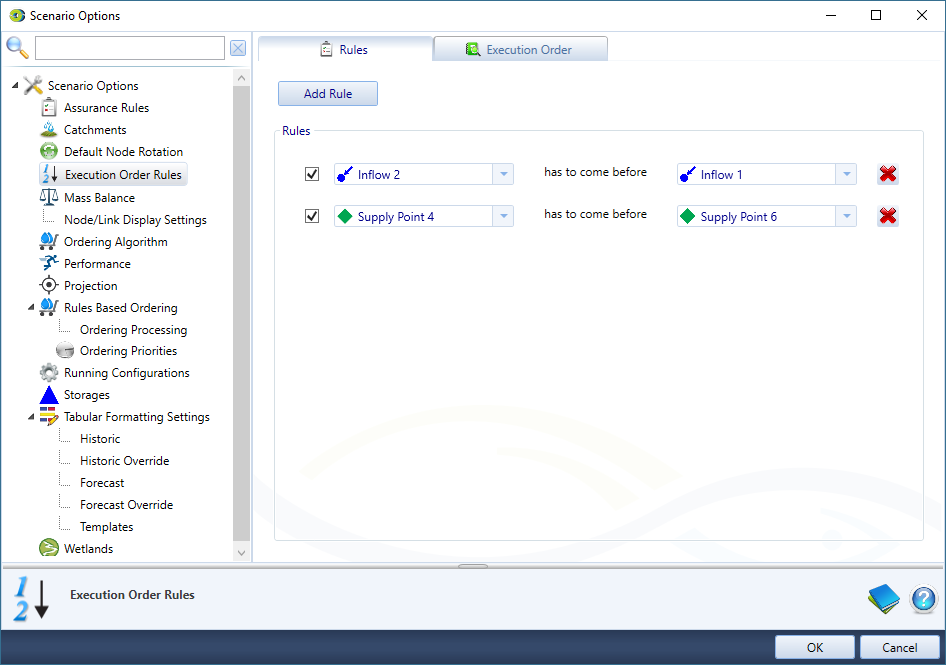
The order can be modified by specifying an execution order rule that one node must be executed before another node. This may be needed if you have function dependencies between different branches of a network (Figure 3).
Figure 3. Scenario Options Execution Order Rules
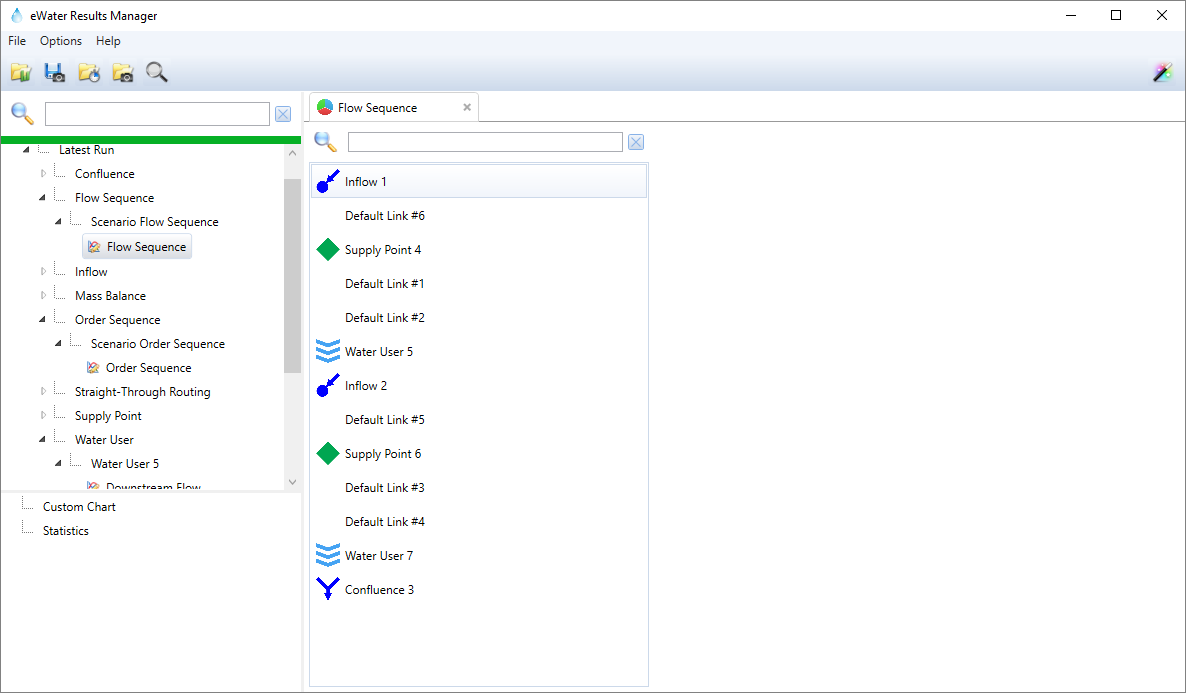
You can record the Flow sequence under Miscellaneous » Flow Sequence » Scenario Flow Sequence
Figure 4. Recording Flow Sequence
Mass Balance
Set the Tolerance Limit for the Mass Balance assurance rule.
Node/Link Display Settings
Display configuration for Nodes and Links in the Geographic and Schematic editor can be set by selecting the appropriate Feature options. This allows the default behavior of the Icons and labels associated with the Feature to be displayed or hidden (Figure 5).
Figure 5. Scenario Options, Node/Link Display Options
Ordering Algorithm
This is where you select between using rules based ordering or network linear programming, and configure network linear programming. Please refer to Ordering for more information.
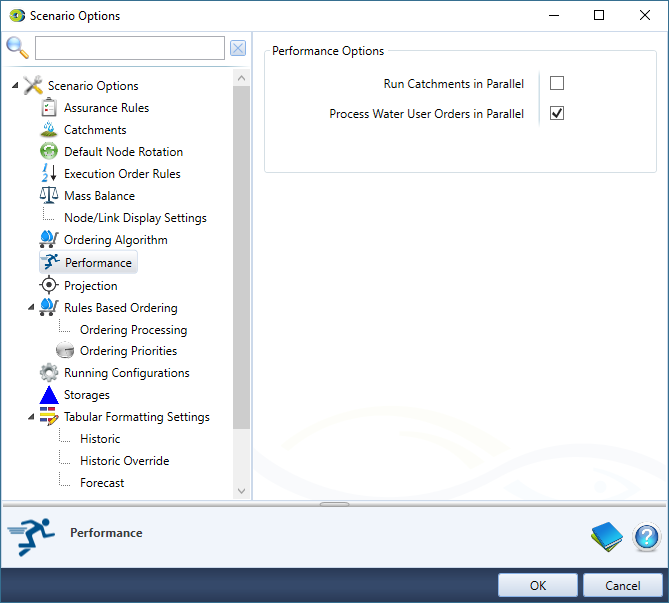
 Performance
Performance
Source was originally designed to perform subcatchment calculations in sequence from the top of the catchment to the bottom. Enabling Run Catchments in Parallel (Figure 5) configures Source to perform subcatchment calculations in parallel within a timestep, and then the node-link network is calculated in the normal sequence, from the top of the catchment to the bottom. This will decrease model run times. This option is only suitable for subcatchments where values are not called from other subcatchments within the same timestep. Currently, it is only possible to call subcatchment values either using a function or in catchment model plugins.
Figure 6. Scenario Options, Performance
Orders generated by water users were previously calculated sequentially from the bottom to the top of the system. As of 3.8.18beta, Process Water User Orders in Parallel is enabled by default, which means that orders are generated simultaneously within a timestep and passed to the supply points. This will decrease model run times.
In a small number of cases that use continuous accounting, the sequence of water user orders may change the results. If necessary, you can toggle off the option, but most users should be able to use the improved performance option without issue.
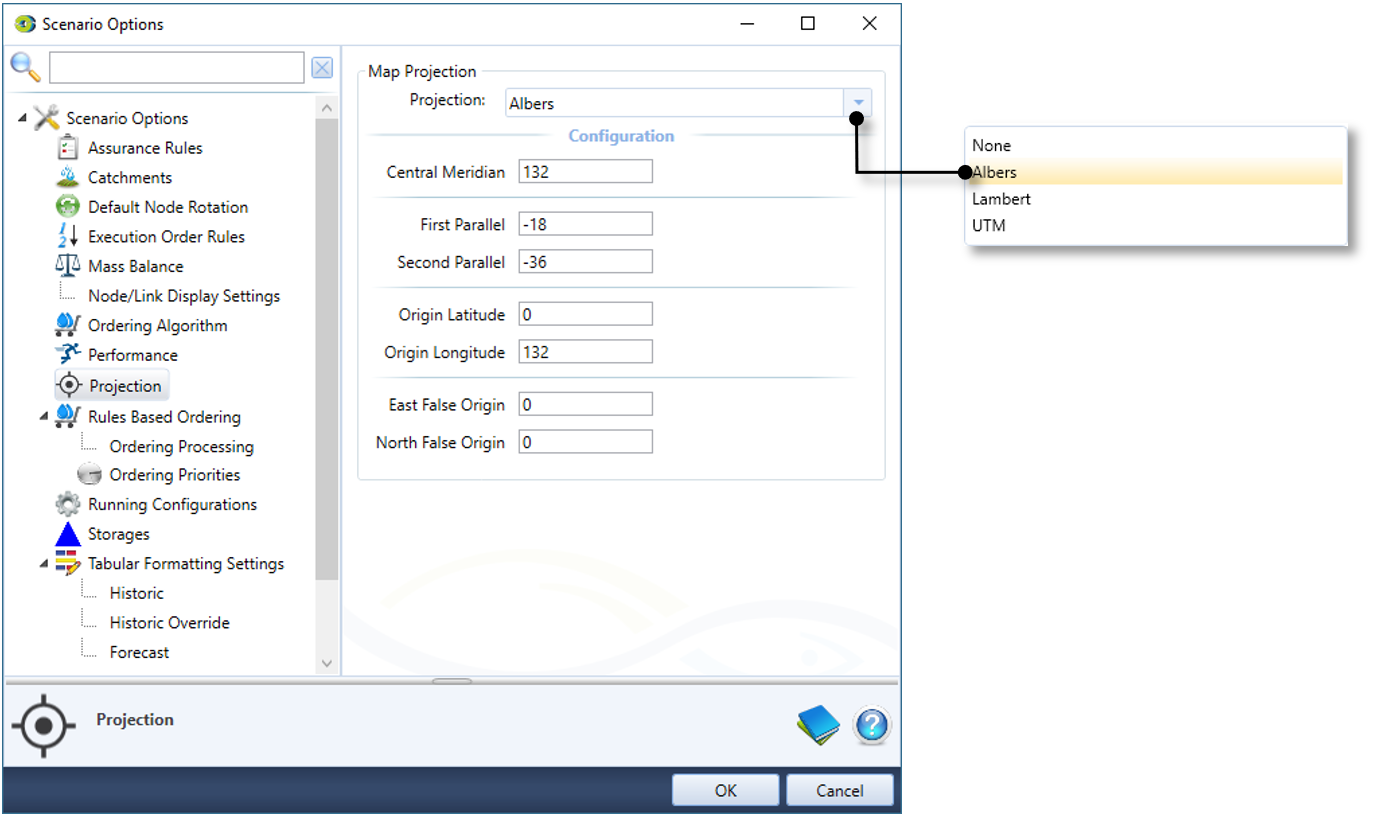
Projection
For catchments scenarios, allows you to convert projected layers from the geographic view to latitude and longitudinal coordinates for the map view (Figure 6). Note that the map view is not available in Source (public version).
Figure 7. Scenario Options, Projection.
Rules Based Ordering
The share shortfalls per owner instead of priorities check box, allows you to specify that the shortfalls should be based on the ownership of the water. For example, if all the water in the river is owned by Owner B, then Owner A will be shortfalled first regardless of the relative priorities of the orders.
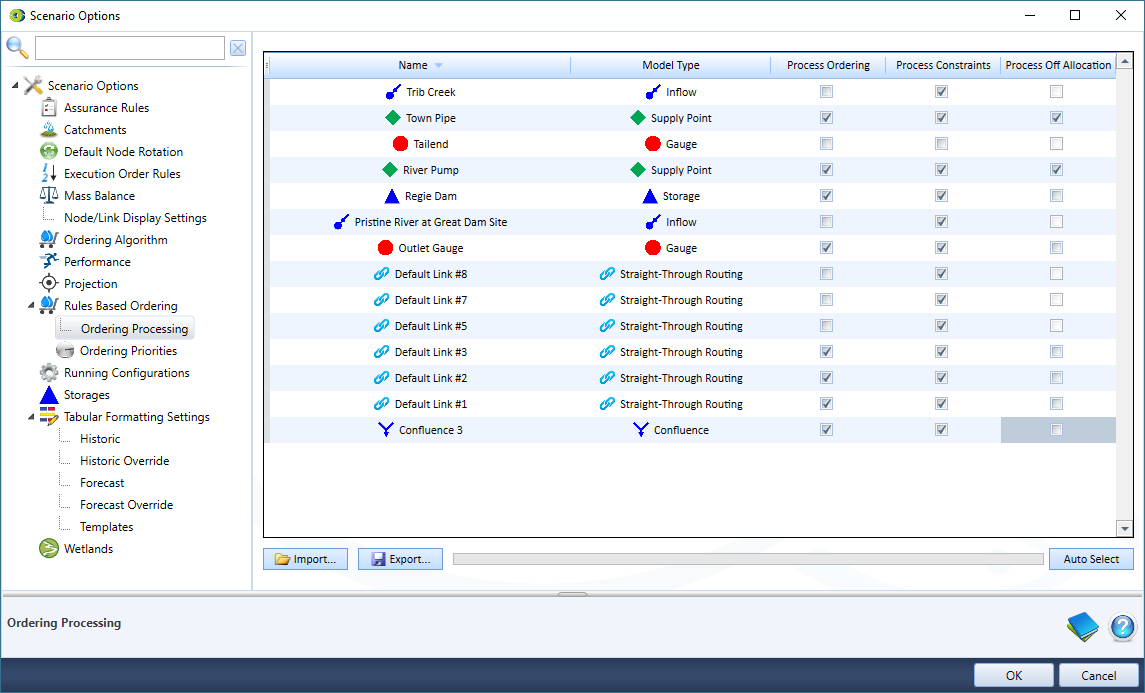
Ordering Processing
By default, Source calculates ordering, constraints and off-allocation for every component in the network, regardless of whether it is on a regulated path. You can choose which components will execute by selecting Rules Based Ordering (Figure 8).
In most cases, using the Auto Select button will select the minimum configuration required for your system. For each component, Auto Select applies the following rules to determine which processes are not required :
- If there is no storage between the component and an unregulated arm of a confluence (going downstream), do not process constraints;
- If the component is above the top most storage, do not process ordering or off allocation;
- If there are no storages downstream from the component (or it is directly above an unregulated confluence arm) and there are no sources of ordering downstream of the component, then turn off all processing; and
- If there is no regulated confluence arm downstream of the component, do not process constraints.
Performance Improvement
Configuring your scenario to only process ordering, constraints and off allocation for appropriate components will reduce model run time.
Figure 8. Scenario options, Rules Based Ordering.
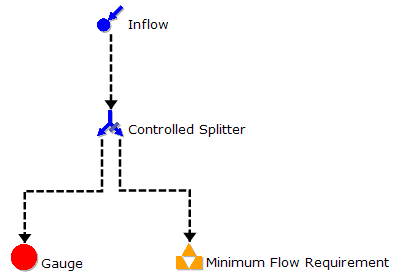
An example where Auto Select does not currently work well is shown in Figure 8. In this case, choosing Auto Select will turn off all processing because there are no storages. However, ordering should be processed for the Minimum Flow Requirement, the Controlled Splitter, the Inflow and the links between them. In this case, you can set the appropriate configuration manually in Rules Based Ordering. This functionality will be implemented in the future.
Figure 9. Example where Auto Select for Rules Based Ordering does not work
Ordering Priorities
Priority ordering is a simple and effective system that allows you to specify how shortfalls are prioritised between different demands in Source (Figure 10). It is set at the scenario level and influences how water is taken by water users and released by storages down different outlet paths. It aids in providing information on how water is supplied to users along regulated river reaches between regulating structures. Pipe Junctions, which represent locations where there is pumped water have the highest priority and will automatically be assigned a priority of n-1. By assigning the Pipe Junction node the highest priority shortfalls are forced to be shared by the Pipe Junction and orders aren't increased t account for the shortfall.
Figure 10. Scenario Options, Ordering Priorities
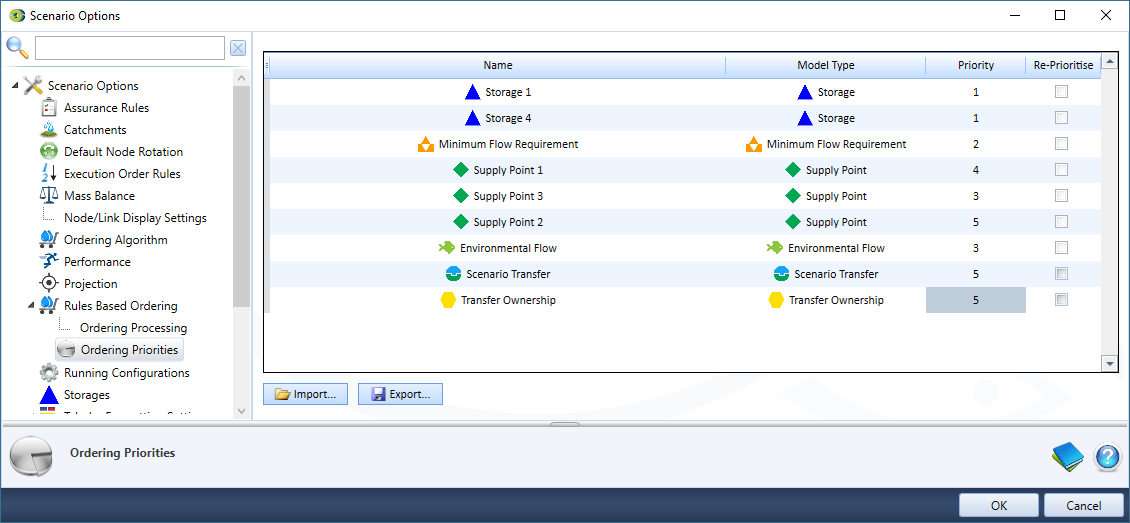
At run time, the ordering system feeds back to the nodes how much water is theirs to take. Not all nodes must have a priority, however, it is important to remember that any node not in the priority table, by default receives the lowest priority.
Note on Priority Ordering at Storages
Re-prioritise Orders
Running Configurations
Running configurations (Figure 11) allow for multiple configurations for each scenario analysis type.
Figure 11. Scenario Options Running Configurations
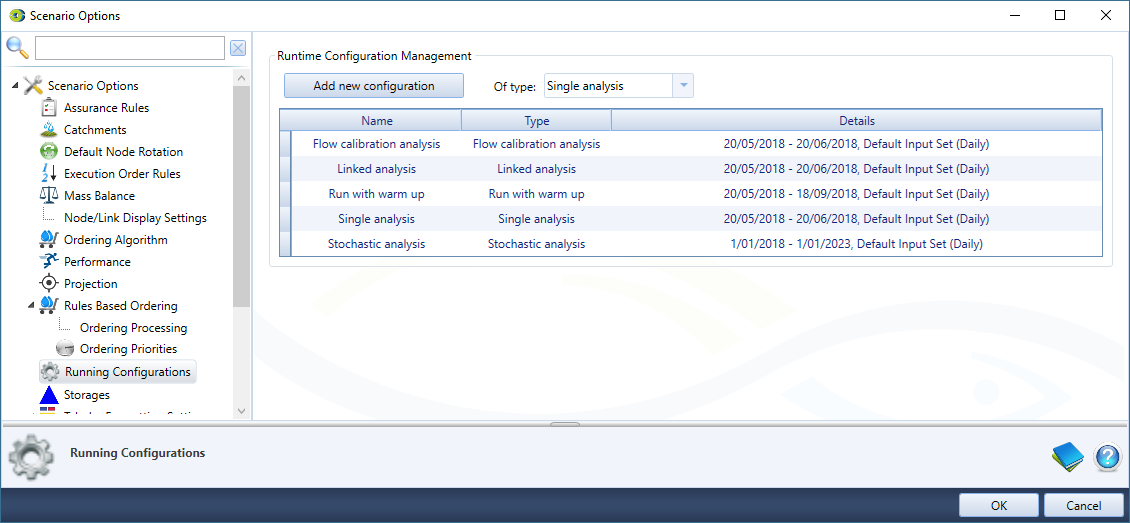
The configuration option will be available to select in the drop down menu on the simulation toolbar. This option is useful for:
- flow calibration analysis where you are configuring calibrations to different gauges, and
- swapping model Time Steps with Scenario input sets, which can now be done seamlessly.
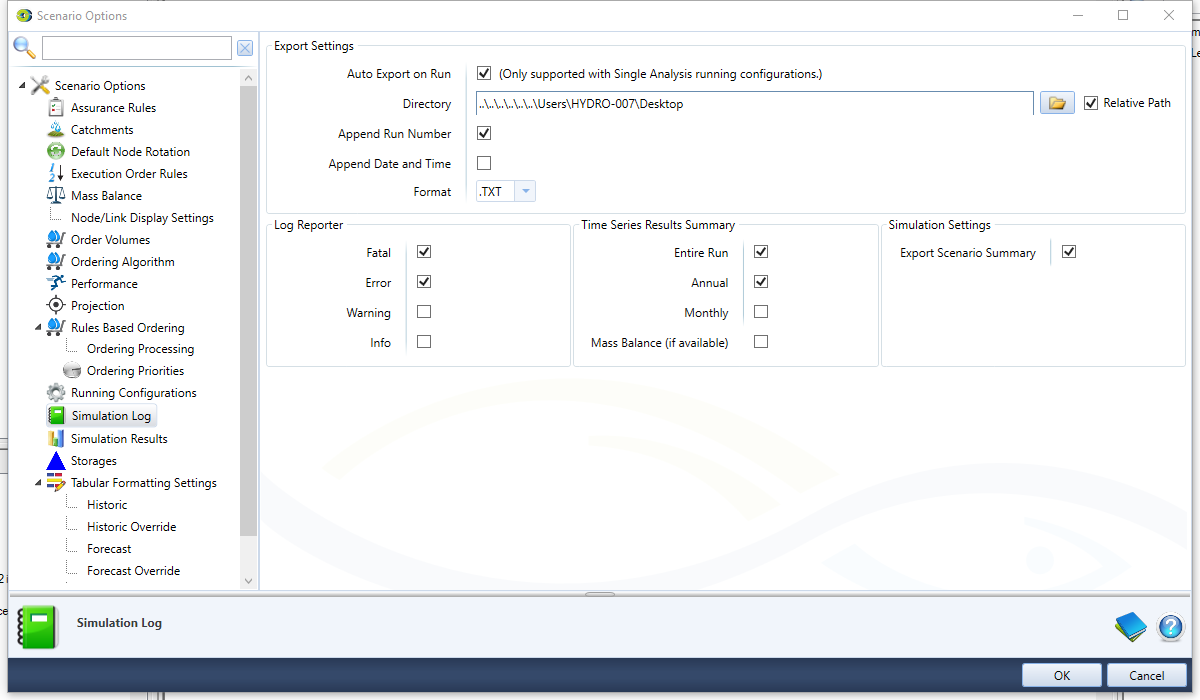
Simulation Log
The simulation log file summarizes the settings and results of a simulation. The Simulation Log allow the user to enable export of the simulation log file, and customise the contents of the file.
Currently, a simulation log file will only be exported for Single analysis Run Configurations.
| Option | Description |
|---|---|
| Export Settings | |
Auto Export on Run | Enables automatic export of the simulation log file at the end of every scenario run. The exported file will be saved to the same directory as the Source project file and will be called SimulationLogFile.txt. If the file already exists, it will be overwritten. If the Source project has not been saved, then the simulation log file will not be exported. The SimulationLogFile.txt is a formatted (fixed column width) text file. The contents of the file depend on the Simulation Log selected by the user. |
| Directory | Define the directory where the exported simulation log file will be saved |
| Append Run Number | Enables automatic export run number to the file name of exported simulation log file |
| Append Date and Time | Enables automatic export date and time to the file name of exported simulation log file |
| Format | Define format of exported results. Two formats are available: .txt and .csv |
| Simulation Settings | |
| Export Scenario Summary | Exports the contents of the Scenario Summary displayed the Results Manager. |
| Log Reporter | |
| Fatal | Export messages from the Log Reporter filtered by the notification level (information, warning, error or fatal) associated with the messages. |
| Error | |
| Warning | |
| Info | |
| Time Series Results Summary | |
| Entire Run | Export summaries of the time series results in the Results Manager. For each time series result, the mean, maximum, minimum and sum will be exported for the selected periods, which can be:
|
| Annual | |
| Monthly | |
| Mass Balance (if available) | If you have set up a Mass Balance in the Results Manager, then it can also be exported as part of the simulation log summary. |
Figure 12. Scenario Options, Simulation Log
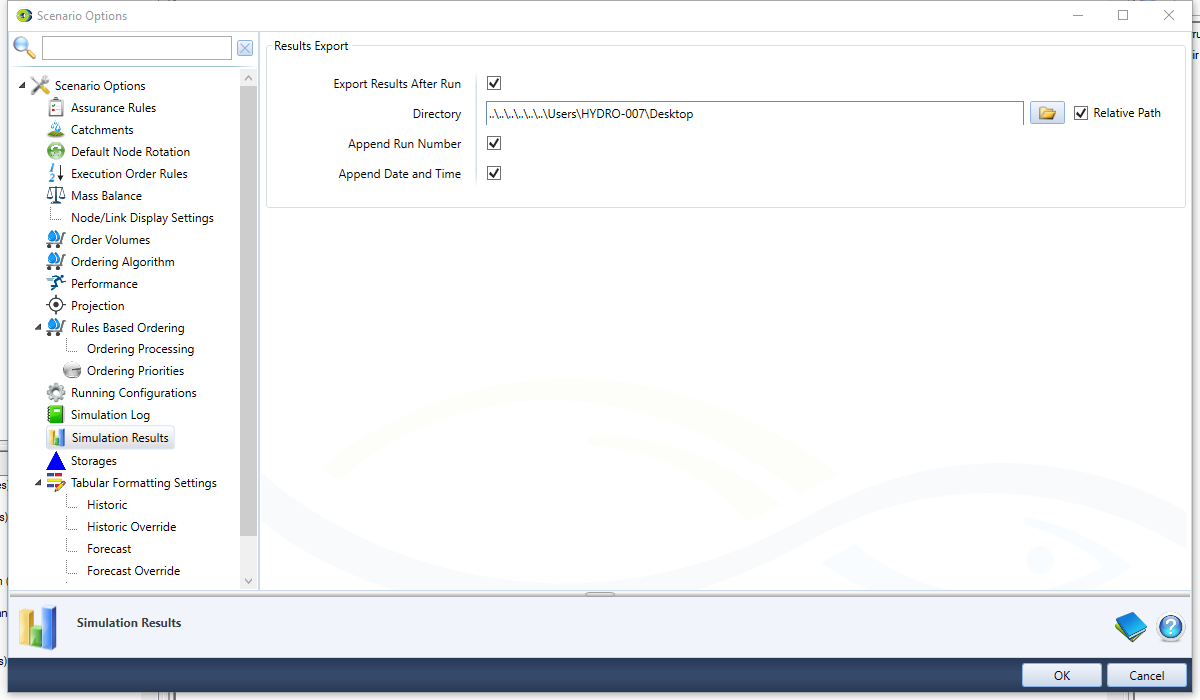
Simulation Results
The Simulation Results allow the user to enable export of recorded results (Figure 13).
| Option | Description |
|---|---|
| Results Export | |
Export Results After Run | Enables automatic export of the results after scenario run |
| Directory | Define the directory where the exported results file will be saved |
| Append Run Number | Enables automatic export run number to the file name of exported results file |
| Append Date and Time | Enables automatic export date and time to the file name of exported results file |
Figure 13. Scenario Options, Simulation Results
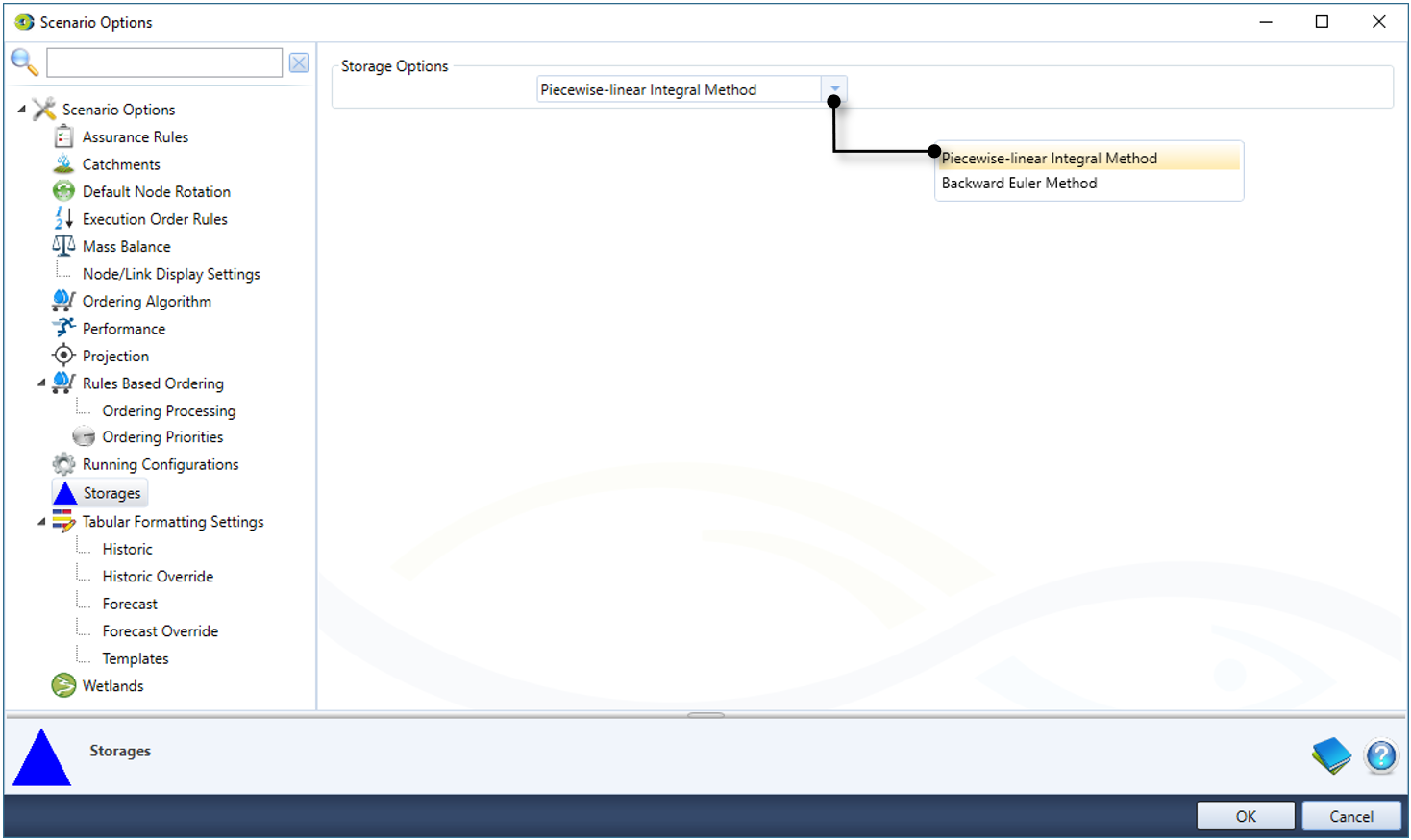
Storages
This section allows you to choose the storage processing method used in the scenario (Figure 14). The Piecewise-linear Integral Method is the default. Selecting the Backward Euler Method enables some functionality. You can configure storage operating levels, and also configure outlet path priorities. For more information, see Storage node - Storage processing method.
Figure 14. Scenario Options, Storages
Tabular Formatting Settings
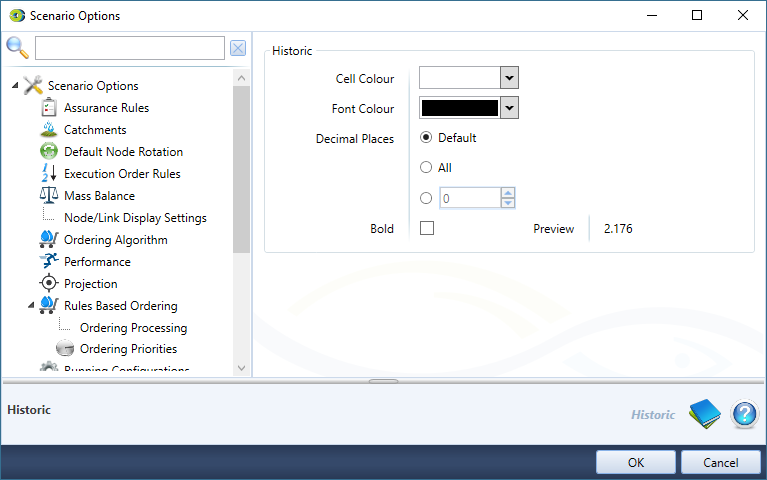
This section allows you to define how values should be displayed in the Tabular Editor (Figure 15) used for River Operations. More information about the Tabular Editor can be fund here (Tabular Editor). Figure 16 shows the settings for Historic values. These configuration options are the same for Historic Override, Forecast and Forecast Override.
Figure 15. Tabular Formatting Settings
Figure 16. Tabular Editor Formatting, Historic
Today
The definition of "today" is the end of the historical period (Today is defined when you click configure on the simulation tool bar after River Operations as been turned on) . The last time-step of the historical period is calculated as the latest time-stamp that is common to all time-series sources in the scenario. You can control the background colour of the cells that are associated with "today" using the Today item.
Cutout
Water takes a finite amount of time to flow through a river system. This lag is represented in the Tabular Editor by discontinuous highlighting. You can control the background colour of the time-associated cells using the Cutout item.
Templates
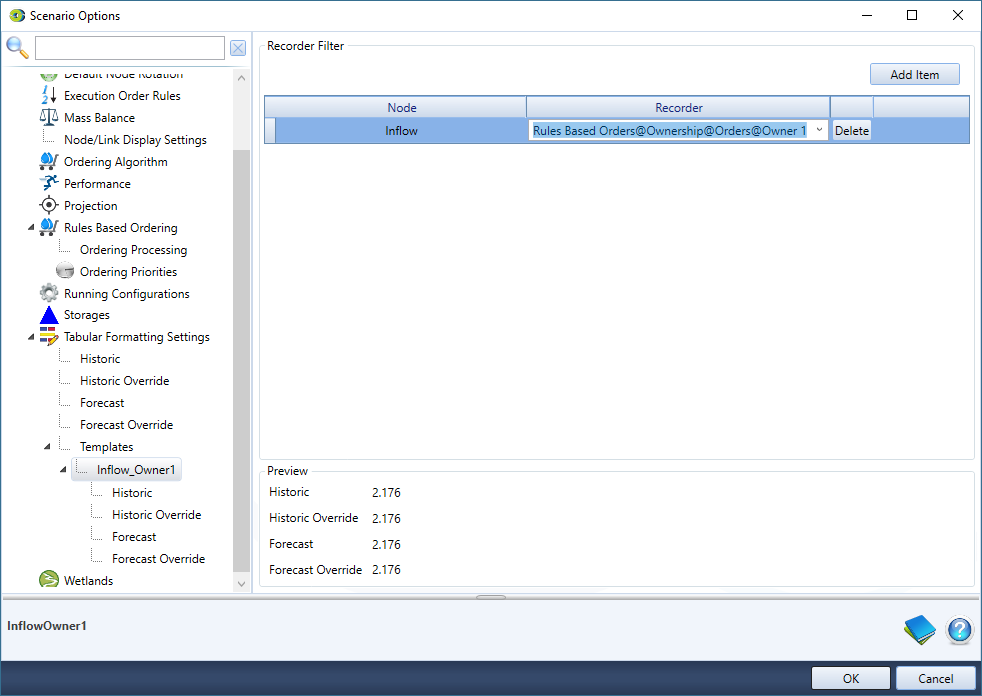
These allow you to set how particular recorders in the Tabular view are displayed. To Add New Template right click on “Templates” and select “Add New Template” (Figure 17)
You can define the appearance of recordable elements for each type of node. To format a cell, add the required node from the “Node” drop down menu. The recorded elements specific to that node will then be available via the “Recorder” drop down menu. (Figure 18)
To format the items, expand the menu for the template and set the format for the four different options. For each recordable element, you can control:
- The colour of the cell background;
- The colour of the text in the cell, and whether the text carries a plain or bold-face stylistic variation; and
- The display precision (number of decimal places).
In addition, you can define distinctive appearances for elements according to whether the underlying data was obtained from:
- A time-series source: Historic Data;
- A value overriding a time-series source: Historic Data (Override);
- A value calculated by a forecasting algorithm: Forecast Data; and
- A value overriding a forecast value: Forecast Data (Override)
As different templates can refer to the same recorder, the Template Priority box is used to determine which template should be used. Where a recorder matches two different templates, the template higher in the list will be used.
Figure 17. Tabular Editor Formatting: Templates
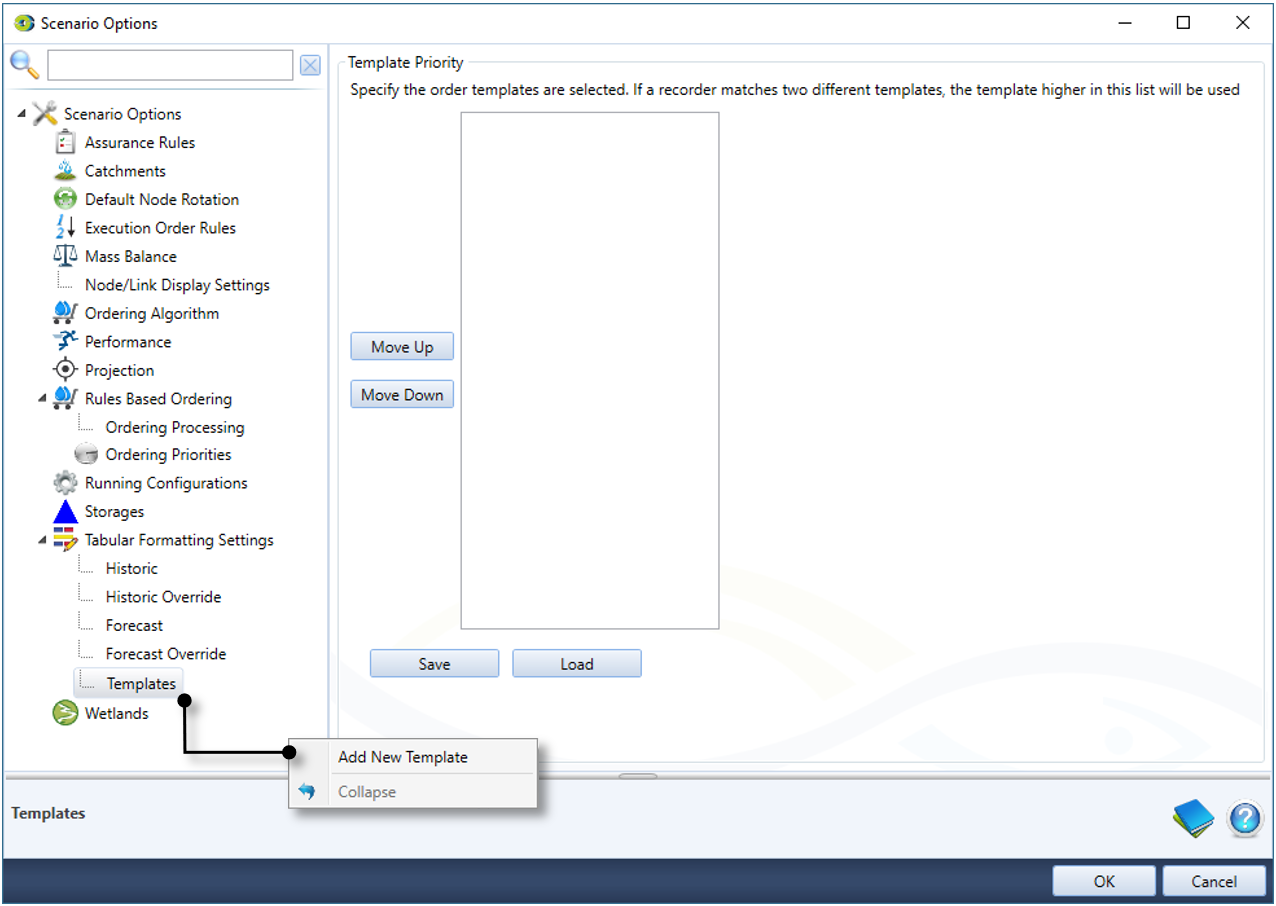
Figure 18. Tabular Editor Formatting: Setting formats for different node types and recorders
Wetlands
These options (Figure 19) are the convergence criteria of the algorithm that finds a solution for each wetland within the scenario. They control how long the algorithm spends finding the best match, and how good that match is.
A solution for a wetland on any given timestep will consist of a number of water surface elevations and conveyance flows between wetland nodes. The solution can be said to have a 'precision' related to the estimated mass balance error of the solution - specifically the precision is the root mean square of the mass balance errors in m3.
Figure 19. Scenario Options, Wetlands
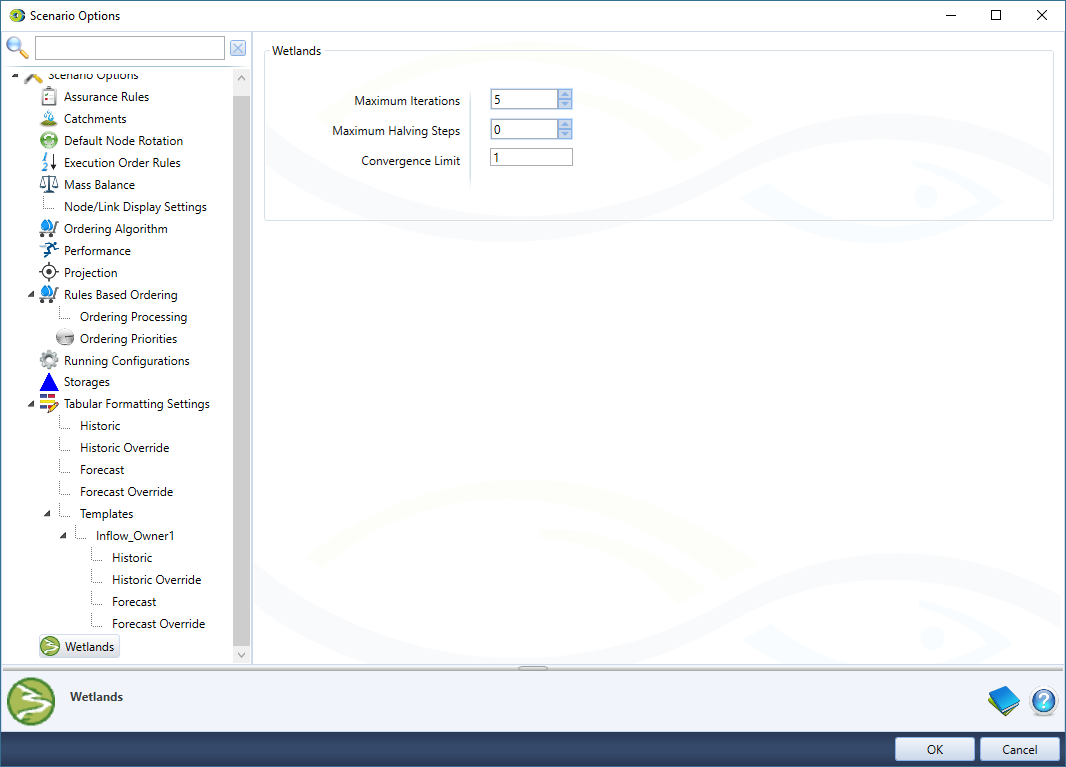
Table 1. Wetland configuration options
| Option | Definition | Notes |
|---|---|---|
| Maximum Iterations | The algorithm uses an iterative approach and will try to stop after this number of iterations. | Generally the algorithm will converge within approximately 5 iterations for most models and timesteps. Certain relastionships can be difficult for the algorithm to solve and a larger number gives a greater likelihood a good solution will be found. It can be a good idea to set a large number of maximum iterations when troubleshooting the wetland components of a model. Iterations will not be used unless the algorithm believes they can improve the result, so there is little harm in a large number. |
| Maximum Halving Steps | Sometimes the algorithm cannot solve a time step as behaviour changes on a sub time step level. This option tells the algorithm to split the time step in half, and solve each half. This splitting can be repeated until this threshold is reached. | If the algorithm cannot find a good solution for a model, and believes this is because of underlying discontinuities, it will create two half length time steps, solve them and then create a composite solution. If the halved time step still has a discontinuity, this will repeat. Warning: this number can dramatically increase run time. A large number of time step halving events tends to indicate a problem in the underlying model. |
| Convergence Limit | The primary criteria for the algorithm to stop iterating. Once the precision of a solution is at or below this threshold it is considered to be 'good enough', and no further iterations will be performed. The lower this number is, the more precise the answer is, but the longer it will take to run. 1 is often a good compromise. | If the algorithm is producing solutions with precisions above the convergence limit it may represent a problem with the model - or it may mean it is simply necessary to spend some more time calculating an answer. Increase the Maximum Iteration and Maximum Halving Steps until the convergence comes within range. If these numbers are quite large and the precision is still to high it is very likely there is an issue with the numbers in your wetland model. |