Note: This is documentation for version 4.11 of Source. For a different version of Source, select the relevant space by using the Spaces menu in the toolbar above
Stochastic Analysis Tool
Incorporating uncertainty into climate variability
The Stochastic Analysis tool in Source is an abridged version of the Stochastic Climate Library (SCL) software available from the Catchment Modelling Toolkit web site, http://www.toolkit.net.au/scl. SCL is a stand-alone program containing several different stochastic models for climate data generation at various spatial and temporal scales.
The Source Stochastic Analysis tool contains a model for the generation of daily rainfall data for multiple sites using the transition probability matrix (with Boughton’s correction). Stochastic climate data can be used as inputs into hydrological and ecological models to quantify uncertainty in environmental systems associated with climate variability. For a detailed description of the multi-site, daily rainfall generation model refer to the Scientific Reference Guide.
Stochastic climate data
Stochastic climate data are random numbers that are modified so that they have the same characteristics (in terms of mean, variance, skew, long-term persistency, etc.) as the historical data from which they are based. Each stochastic replicate (sequence) is different, and has different characteristics compared to the historical data, but the average of each characteristic from all stochastic replicates is the same as the historical data.
Using historical climate data as inputs into hydrological models provides results that are based on only one realisation of the past climate. Stochastic climate data provide alternative realisations that are equally likely to occur, and can therefore be used as inputs into hydrological and ecological models to quantify uncertainty in environmental systems associated with climate variability. Stochastic climate data are traditionally used in storage yield analysis to estimate reservoir size for a given demand and reliability, or to estimate system reliability (number and levels of water restrictions) for a given storage size and demand characteristics.
Using the stochastic analysis tool
Use the Stochastic analysis dialog:
- In the Simulation toolbar, change the analysis option to Stochastic Analysis; and
- Click Configure
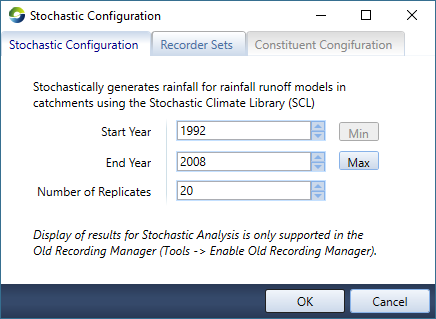
The Stochastic Configuration dialogue opens (Figure 1). To begin the analysis:
- Define the Start and End years;
- Specify the number of replicates to run. The default is 20;
- Click OK; and
- In the Simulation toolbar, click Run.
The Stochastic Analysis tool will automatically load the rainfall data that is being used by the scenario, and then stochastically generate rainfall replicates for each sub-catchment.
Figure 1. Configuration, Stochastic Analysis
The Stochastic Analysis tool may take some time to complete, depending on the number of sub-catchments, replicates, number of recorded variables and type of rainfall data used in the scenario. Generally, the more complex the model or scenario, the longer the stochastic generation of rainfall data will be.
 To produce valid results when comparing statistics from the generated and historical data, the replicate length and the historical input data length must be the same. To properly capture sampling variability, you should also generate at least 100 replicates. |
Once the Stochastic Analysis tool has finished, the modelled flow and constituent parameters appear in the Recording Manager and can be viewed by selecting the parameter of interest in the right-hand column of the Recording Manager. The new Results Manager, which is the default viewer for single analysis, does not currently support stochastic analysis.
Viewing and assessing statistical results
A list of all available statistics is displayed in the top, middle window under Statistics. To view a particular statistic, select it under Statistics to view the data as a box and whisker plot, which shows the spread of data. Figure 2 shows the monthly mean plot for one of the nodes in the model.
Figure 2. Box plot of mean monthly flow replicates
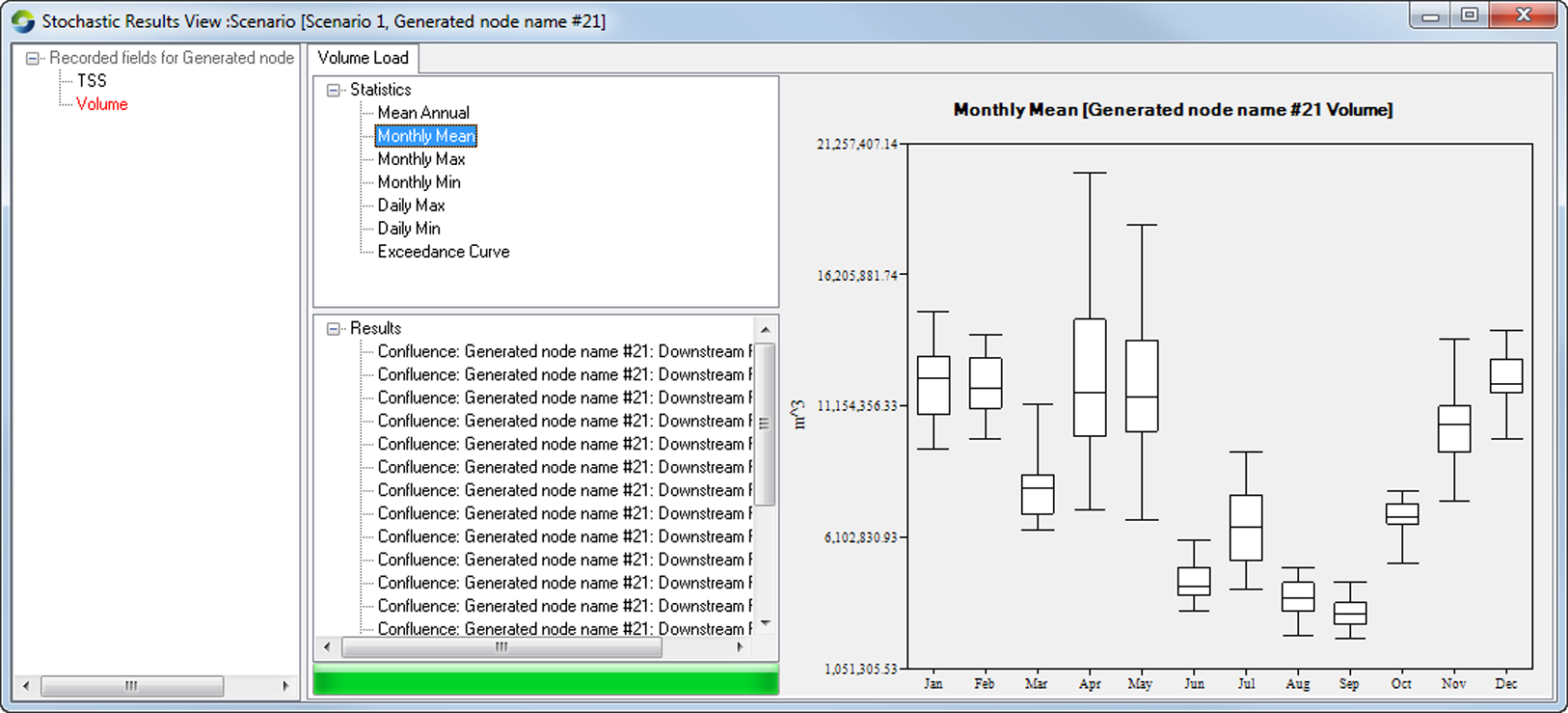
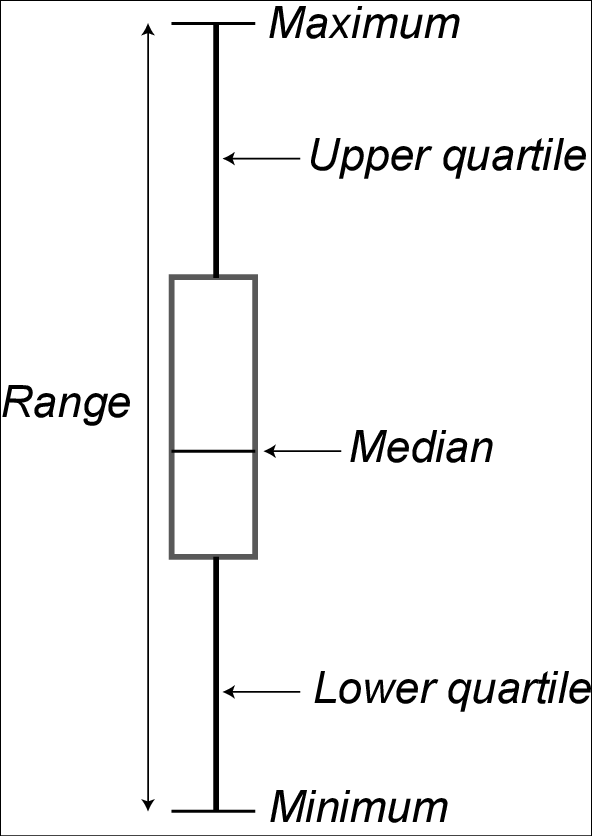
Figure 3 shows how a box and whisker plot represents the distribution of data.
Figure 3. Box and whisker plot
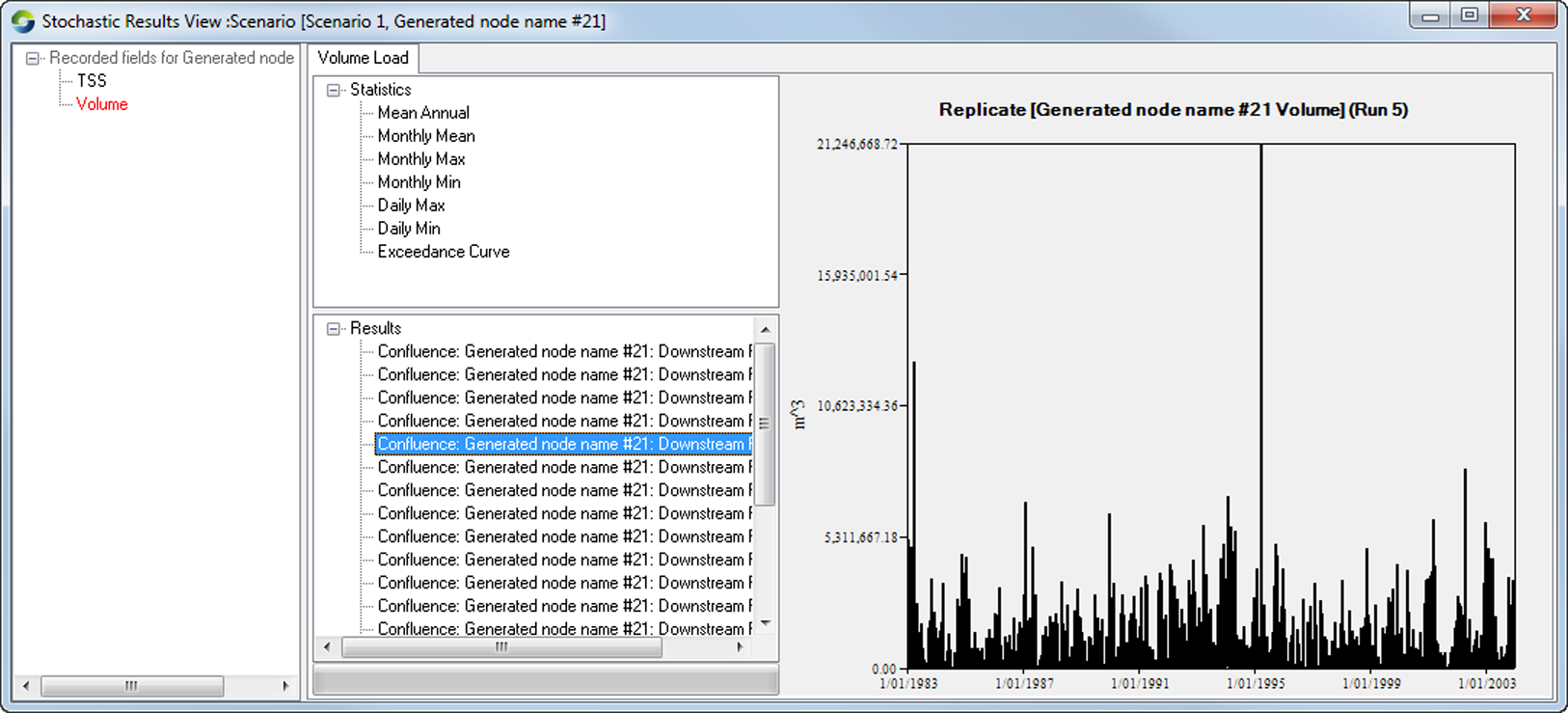
A new screen appears with the stochastically generated flow and constituents replicates and statistical outputs (Figure 4).
Figure 4. Stochastically generated flow replicates
Limitations and cautionary notes
Although stochastic hydrology is a mature science, new stochastic models are continually being developed, usually with marginal improvements on previous models. The modelling approach for generating stochastic rainfall data has been selected because of available expertise, the model’s robustness, along with extensive and successful model testing using data from across Australia.
A basic understanding of stochastic climate data is required to properly use stochastic data with hydrological and ecological models to quantify uncertainty in environmental systems associated with climate variability. The user should consider the following questions when designing a stochastic and hydrological modelling study:
|
The Stochastic Analysis tool can take a long time to run, particularly when applied to large catchments and when you have specified many replicates (ie over 100). Such applications can take several hours to run. Therefore, when first designing a scenario with stochastically-generated rainfall data, keep the following in mind:
- Perform a "dummy" run with only a few replicates (< 20) to assess whether or not the stochastically-generated data is being generated properly;
- Be specific about what you need to record. If the flow that is coming out of the catchment outlet is of particular interest, then only record the catchment outflow when using the Stochastic Analysis tool. All other parameters and reporting options can be set to Record None. This will reduce the repeat run time and reduce the size of the generated output data; and
- Make note of how many years of data you want to generate climate data for. Although it is desirable to use as much data as possible, only use what you need to get a satisfactory model result.
As a general rule, the input data should have at least 20 years of historical climate time-series data. As an absolute minimum, the stochastic analysis requires a climate record of 5 years. Longer data is used to improve the calibration of the stochastic model to the characteristics of the historical time series. In addition, the model needs to be configured with at least two distinct time series inputs. |